機械学習モデルの汎化性能を向上させる方法の基本まとめ【Pythonサンプルコードあり/グリッドサーチ】

目次
こんにちは。
今回は機械学習で作ったモデルの汎化性能を向上させる方法をまとめます。
最近このブログではペンギンデータセットを使った機械学習入門というシリーズで記事を書いているのですが、その続編です。
主に教師あり学習の分類モデルに対して「グリッドサーチ」という手法で精度向上を試みます。
機械学習モデルの 「汎化性能」 とは
機械学習で作成されたモデルは使用する教師データ(訓練データ)に依存するため、その用意されたデータに過剰に適合している場合、他の未知のデータに対して正しく予測・分類する性能が落ちてしまいます。
機械学習のモデルの目的はできるだけ未知のデータに対しても精度良く予測することなので、どのようなデータが来てもそれなりに正しく予測できる性能が求められます。これが「汎化性能」(generalization performance)と呼ばれている性能です。
モデルを作成する際には、「手元にあるデータを使って、いかに汎化性能を高くするか?」ということを考える必要があります。
グリッドサーチ (grid search) とは
汎化性能の高いモデルを作成するには選択したアルゴリズムに対してハイパーパラメータのチューニングを行う必要があります。そこで汎化性能が高いモデルを作ってくれるパラメータを「探索」する代表的な方法がグリッドサーチです。
簡単に言うと、「パラメータの組み合わせを次々に試していって、最も精度が良いモデルを作るパラメータを探す」、という方法です。
グリッドサーチの前準備 1. データセットのロード
今回は決定木分析のモデルに対してグリッドサーチを使ってみます。例によってペンギンデータセットをロードして必要な列を抽出しておきます。
関連記事 : ペンギンデータセットで機械学習/データサイエンスをはじめよう〜ダウンロード編
※特徴行列Xと目的変数yが用意できればペンギンデータセットでなくても何でもいいです。
import pandas as pd
df = pd.read_csv('penguins.csv')
df = df.drop(columns=['island','sex','year'])
df = df.rename(columns={
'bill_length_mm' : 'bill_length',
'flipper_length_mm' : 'flipper_length',
})
df = df[['species','flipper_length','bill_length']]
df = df[~df.isnull().any(axis=1)]
X = df.drop(columns='species').values
species = df.species.unique()
species_number_map = { species[i] : i for i in range(len(species)) }
species_number_map # {'Adelie': 0, 'Gentoo': 1, 'Chinstrap': 2}
y = df.species.map(species_number_map)
特徴行列Xは羽の長さとくちばしの長さ、目的変数yはこのspeciesを数値変換したものです。
グリッドサーチの前準備 2. データセットを訓練セット・検証セット・テストセットに3分割する
過去の記事でご紹介した交差検証法では、汎化性能を確認するためにデータセットを「訓練セット」「テストセット」の2つに分割していました。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=42) # データセットをtrainとtestに2分割
しかし、この2分割でパラメータ探索してモデルを作る(=チューニングする)と、テストセットの方もパラメータに影響を与えるため、モデルがデータセットに過剰適合して汎化性能が失われてしまう可能性があります。
そこで、パラメータチューニングをしたい場合は、訓練セットをさらに2つに分割します。
# split for paramter tuning
from sklearn.model_selection import train_test_split
X_trval, X_test, y_trval, y_test = train_test_split(X,y,random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(X_trval, y_trval, random_state=0)
それぞれサイズを見てみると、以下のように分割されました。train_test_splitはデフォルトだと75:25(=3:1)に分割されます。
X.shape # (342, 2) ... 元のデータセット
X_trval.shape # (256, 2) ... 訓練セット&検証セット
X_train.shape # (192, 2) ... 訓練セット
X_valid.shape # (64, 2) ... 検証セット
X_test.shape # (86, 2) ... テストセット
参考 : scikit learn | sklearn.model_selection.train_test_split
と、これはまあ基本の考え方なのですが、実はグリッドサーチと交差検証を同時にやってくれる関数が既に用意されています。
なので、その関数を使えば訓練セット&検証セット、テストセット、という2つに分割されていれば十分だったりします。これについては後述。
グリッドサーチの交差検証をPython scikit-learnで実現する方法 ~ GridSearchCV
それでは上記のデータセットを使ってグリッドサーチによるパラメータチューニングを実践してみます。
原理がわかりやすいのでFor文でも簡単に実装できそうですが、scikit-learnではmodel_selectionモジュールのGridSearchCV関数が用意されているので、これを使ってみます。
この関数には名前にCVとついているように、グリッドサーチするだけでなく「交差検証(CV, Cross Validation)」も同時に行って最適なパラメータを選定してくれます。
交差検証の詳細はこちらの記事を参照 : 機械学習モデルの汎化性能を検証する方法の基本まとめ【Pythonサンプルコードあり/交差検証法/ホールドアウト法】
一般的に「交差検証」と言うと、単に「データセットを分割して試行を繰り返すこと」だけでなく、「グリッドサーチしてパラメータを探索すること」までを含めることが多いようです。
使用するデータセットは先程分割したデータのうち、X_trvalを交差検証に、X_testを最終的なテストに使用します。(trainとvalidの分割は関数内で内部的に行われます。なので、予め自分で分割しておく必要は実はありません。)
from sklearn.tree import DecisionTreeClassifier # 決定木のモデルをインポート
from sklearn.model_selection import GridSearchCV # グリッドサーチの関数をインポート
estimator = DecisionTreeClassifier() # 決定木の推定器インスタンスを作成
param_grid = {'max_depth':[5,10,20],'min_samples_split':[5,10,20]} # パラメータの組合わせを設定
clf = GridSearchCV(estimator, param_grid, cv=5) # グリッドサーチ & 交差検証
clf.fit(X_trval, y_trval) # 訓練&検証セットでフィッティング
GridSearchCVの主なパラメータはestimator、param_grid、cvの3つです。それぞれ推定器のモデルインスタンス、探索するパラメータ、交差検証の分割数を渡します。
探索するパラメータは、学習するモデル(ここではDecisionTreeClassifier)ごとに特有のパラメータなので、先にどのようなハイパーパラメータがあるのかを調べておく必要があります。間違えると、エラーになったり予想と反する結果になる可能性があるので注意が必要です。
今回は、決定木の枝分かれの最大数であるmax_depthと、分割後のサンプルの最小数であるmin_samples_splitを探索することにしました。だいたい決定木はこの辺りを弄ることでデータセットに対する過剰な適合、つまり過学習を防ぎ、汎化性能を向上させることができます。値は試しに5,10,15の3パターンをそれぞれ調べてみます。param_gridを引数に渡すときは辞書型で、パラメータ名をキー、パラメータの候補をリスト型の値とします。
参考 : scikit learn | sklearn.model_selection.GridSearchCV
ちなみに、scikit-learnのドキュメントでもグリッドサーチのインスタンス名に使われているclfとは分類器(classifier)の略らしいです。
グリッドサーチの結果の見方と活用方法
上のようにフィッティングを実行したあと、どのようにグリッドサーチの結果を活用すればよいかをまとめておきます。
まず、グリッドサーチの目的は「パラメータの探索」だったので、見つかった最適なパラメータを知りたいですよね。
clf.best_params_
# {'max_depth': 5, 'min_samples_split': 5}
このようにフィッティングしたインスタンスclfに対して.best_params_を呼び出すと、最適なパラメータのセットを得ることができます。今回はどちらのパラメータも5のとき、最も交差検証の平均スコアが高かった、ということですね。
探索の結果をより詳細に知りたい場合は、以下のようにします。
pd.DataFrame(clf.cv_results_).T
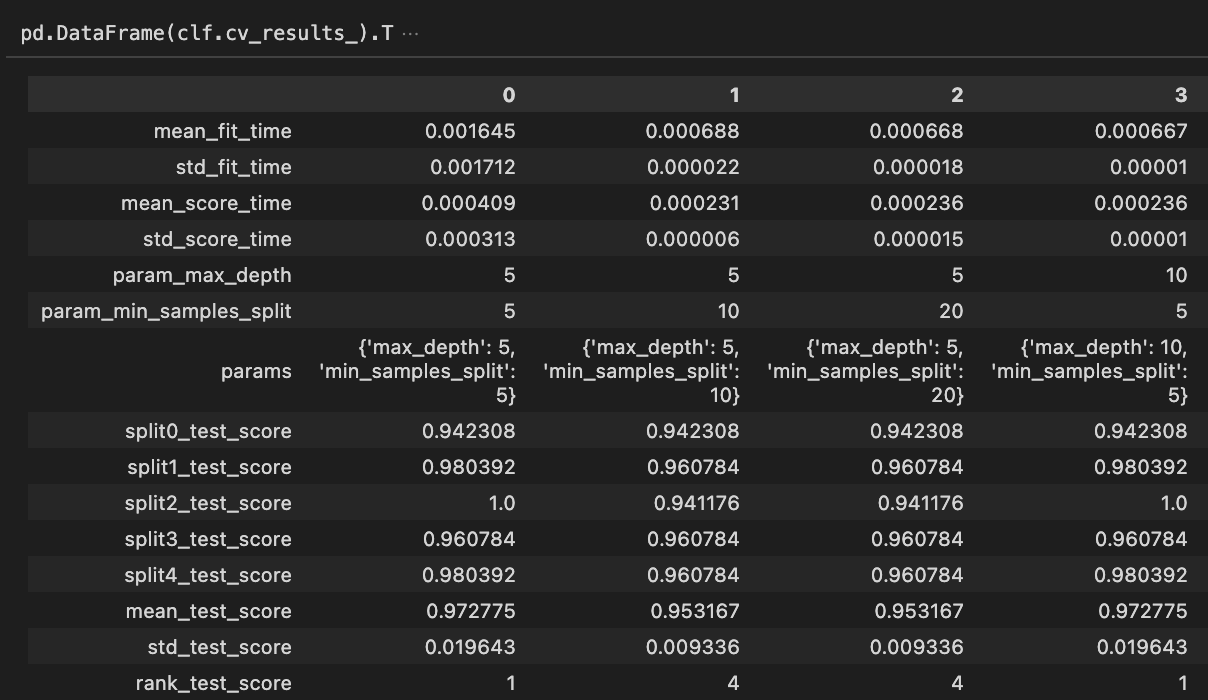
見やすくするためデータフレームにして転置してみましたが、要は.cv_results_で交差検証の結果をまとめて取り出すことができます。このように各試行(パラメータの組み合わせ)毎の計算時間やスコアをまとめて確認できます。結果として特に注目したいのは探索パラメータparamsと平均スコアmean_test_scoreですね。これらを元に上記のbest_params_が返ってきます。
グリッドサーチのメリットとデメリットは何か
上の結果をよく見たらパラメータ(10,5)のパラメータセットでもベストパラメータと同様の精度で分類できていることがわかります。先程はざっくりとしたパラメータの組み合わせだったので、もう少し細かく探索してもよさそうですね。次は[3,4,5,6,7,8,9,10,11,12]でやろうか、などとより探索対象を細かく多くしていくと、理想的なパラメータに近づいていきます。何回かに分けて段階的に詰めていくという方針が良さそうです。
ただし、パラメータの組み合わせが増えるほど計算時間が増えてしまいます。単純計算だと、「組み合わせの数×交差検証の分割数」だけ時間が増えます。
このようにグリッドサーチはすべてのパラメータの組み合わせを簡単に確かめられるというメリットはありますが、組み合わせの数によって計算時間が単純に増えてしまうというデメリットがあります。
グリッドサーチで探索した最適なパラメータのモデルをテストする方法
最後にグリッドサーチで見つけた最適なパラメータのモデルを使ってテストしてみます。
最初にデータセットを分割するときに用意したX_testとy_testの出番です。
clf.score(X_trval, y_trval) # 訓練&検証セットに対するスコア : 0.9921875
clf.score(X_test, y_test) # テストセットに対するスコア : 0.9302325581395349
結果、テストセットに対して93%の精度で予測できました。(さすがにパラメータがざっくりしすぎてまだ精度が低い?もしくはデータ数が少ないのかも?)
要は、このようにGridSearhCVで作ったインスタンスclf自体がfit、score、predictなど今まで出てきた普通のモデルインスタンスと同じように使えるということです。clf.predict(X_test)で予測した目的変数のベクトルも取得できます。
clf.best_estimator_で最適なモデルを取り出すこともできますが、上記の方法clf.scoreで十分です。
まとめ
というわけで今回は機械学習の分類モデルに対して汎化性能を向上させるために「グリッドサーチ」という方法をご紹介しました。
この方法を使えば、最適なパラメータの組み合わせを探し出し、かつ交差検証も行うことで汎化性能の高いモデルを作ることが出来ます。Pythonのscikit-learnでGridSearchCVを使うことで簡単に実装できました。交差検証の結果確認、モデルのテストも簡単にできました。
ご参考になれば幸いです。
それでは〜
関連記事
機械学習モデルの汎化性能を検証する方法の基本まとめ【Pythonサンプルコードあり/交差検証法/ホールドアウト法】
機械学習の分類モデルの評価指標・混同行列についての基本まとめ【Pythonサンプルコードあり/3分類以上でも簡単】
【データサイエンス入門】決定木分析をPythonで簡単に試す & 分類と条件分岐を可視化する方法まとめ【サンプルコードあり】
ペンギンデータセットでデータサイエンス入門 〜 教師あり学習・分類編【Python/scikit-learn/機械学習/ガウシアンナイーブベイズ】
ペンギンデータセットでデータサイエンス入門 〜 機械学習の基本・単回帰編【Python/scikit-learn/教師あり学習】

