ペンギンデータセットでデータサイエンス入門 〜 機械学習の基本・単回帰編【Python/scikit-learn/教師あり学習】

目次
こんにちは。
さて、昨今データサイエンス入門者に爆発的な人気を誇っているpalmerpenguinsなるペンギンデータセット。前回の記事でデータセットを可視化しました。
今回はペンギンデータセットを使って機械学習とは何たるかを学びましょう。
という初心者向けの記事です。
よろしく。
ちなみに本記事ではプログラムにPython3と、機械学習ライブラリにscikit-learnを使います。
過去の関連記事はこちらです。
- ペンギンデータセットで機械学習/データサイエンスをはじめよう〜ダウンロード編
- ペンギンデータセットでデータエンジニアリングの基礎を学ぼう
- ペンギンデータセットでデータサイエンス入門 〜 特徴行列の可視化編
データセットの準備
まずは今回使うデータセットをインポートします。データエンジニアリング編で作ったデータセットを読み込んで、必要な列だけ取り出します。列名は使いやすいように短く変換します。
import pandas as pd
df = pd.read_csv('penguins.csv')
use_col = [
'species',
'bill_length_mm',
'bill_depth_mm',
'flipper_length_mm',
'body_mass_g',
]
df = df[use_col].rename(columns={
'bill_length_mm':'bill_length',
'bill_depth_mm':'bill_depth',
'flipper_length_mm':'flipper_length',
'body_mass_g':'body_mass'
})
こんな感じのデータになります。
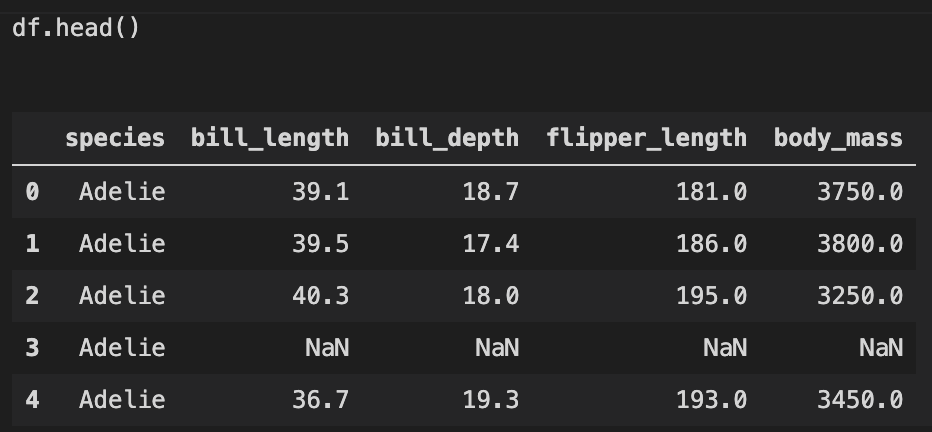
機械学習の前に、データセットのクレンジング ~ 欠損値NaNの除外
今回はフリッパー(羽)のサイズからペンギンの体重を予測するモデルを作ろうと思います。
本題とずれますが、実はデータセットに注意があり、どちらの列も欠損値NaNを含んでいます。.isnull().any()のメソッドでデータフレームの列に1つでも欠損値があればTrueで返ってくるので、これで調べられます。
df = df[['flipper_length','body_mass']]
df.isnull().any() # どちらの列もTrue、つまりNaNの行が存在する。
これらのNaNの行は学習の邪魔なので先に除外しておきましょう。どちらか一つでもNaNがあれば使えません。「どちらもNaNではない」列のみ取り出してデータフレームを更新します。.isnull().any()はaxis=1を指定すると、各行に対してnullがあるか判定します。~で反転することで、どちらも欠損していない列がTrueになり、取り出すことができます。
df = df[~df.isnull().any(axis=1)]
準備完了です。
scikit-learnを使った機械学習の手順
それでは、scikit-learnで機械学習とは一体どんなことをするのかを知りましょう。手順をざっくりまとめると以下のような流れになります。
- モデル選択
- モデルのインスタンス化とハイパーパラメータの選択
- 特徴行列と目的配列の設定
- フィッティング
- 未知のデータを予測
...なんのこっちゃ。
次の章で具体的に試していきます。今回は最も基本的な教師あり学習の単回帰を実践しながら機械学習の流れを追ってみたいと思います。
機械学習の手順1. モデル選択
ここでは推定器のクラスをインポートしてモデルを選択します。
今回は単回帰をしたいので、線形回帰用のモデルLinearRegressionクラスをインポートします。
from sklearn.linear_model import LinearRegression
Linearが線形で、Regressionが回帰という意味。
パラメータの説明や使い方の詳細は scikit-learnのドキュメントで。
機械学習の手順2. ハイパーパラメータを選択
ここではクラスをインスタンス化してモデルのハイパーパラメータを選択します。
先程インポートしたクラスをインスタンス化する必要があります。その際に、ハイパーパラメータの選択も行います。例えば線形回帰でいうと、「切片を使うかどうか?」といった選択肢を決めることです。普通の関数を使うときに指定する引数のようなパラメータより、一歩外側にあるイメージなので、「ハイパー」。
今回は切片を計算する(原点を通るとは限らない)モデルに適合したいため、fit_interceptというパラメータを指定して使います。
model = LinearRegression(fit_intercept=True)
機械学習の手順3. 特徴行列と目的配列の設定
ここではデータセットを特徴行列と目的配列に設定します。
先程クレンジングの章で書いた通り、今回はペンギンデータセットからフリッパー(羽)の長さflipper_lengthと体重body_massの関係をモデルにしたいと思います。
どんなデータか見てみると、こんなデータです。データフレームのplotメソッドが使えます。
df.plot.scatter('flipper_length','body_mass')
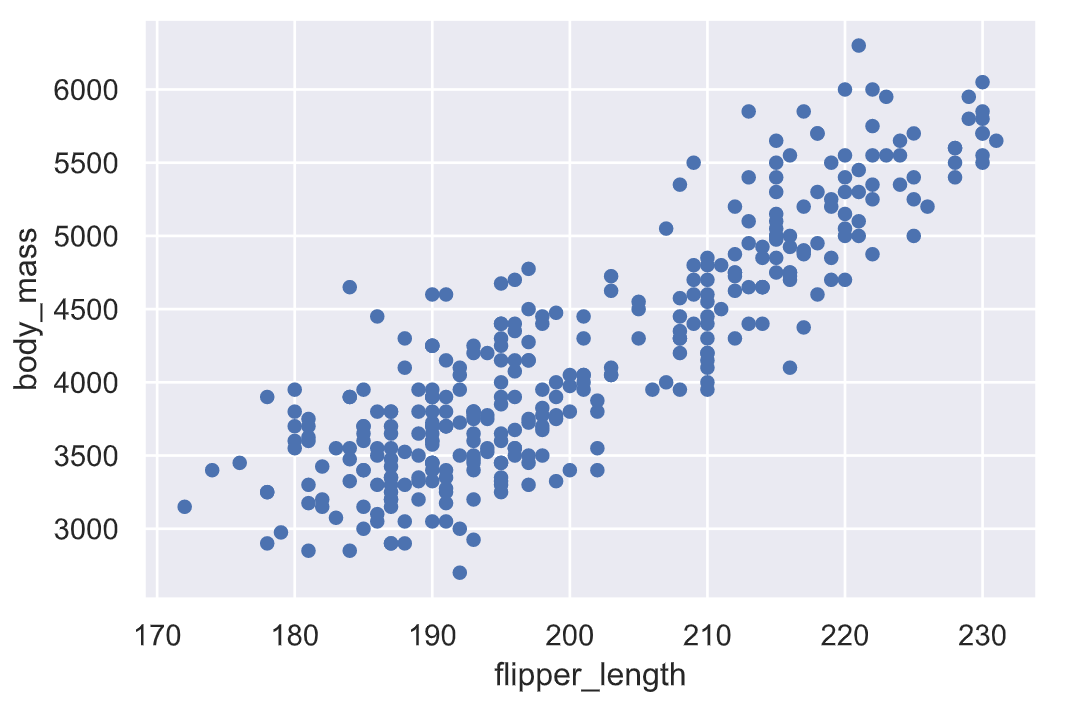
いかにも直線性がありそうなデータですね。まあ羽が大きければ体が大きくて体重も重いでしょう、ということなので当たり前です。こういうわかりやすいデータから取り掛かっていくのも大事。
これらの列をモデルにセットするため、変数にします。通常、予測したい目的変数がyで、説明変数がxです。説明変数になる特徴量は複数あることが多く、大体は行列になるので大文字Xを使うことが多いです。今回は予測したいbody_massがyで、flipper_lengthをXとします。
y = df.body_mass.values[:-10]
x = df.flipper_length.values[:-10]
X = x.reshape(len(x),1)
実はデータフレームから取り出してもそのまま使えないので、一旦.valuesで配列にして、.reshape()で配列を形状変更する必要があります。ちょっとめんどい。
.values[:-10]の部分は、配列のラスト10個を取り除いています。ラスト10個はこの後の手順5で予測に使う未知のデータとしてとっておきたいため、学習で使わないようにここで除外しています。
機械学習の手順4. フィッティング
ここではインスタンスのメソッドを使ってモデルをフィッティングします。内容は統計モデリング的なフェーズですが、使うメソッドはfit()で一行で終了します。
model.fit(X,y)
以上終わり。完。
結果として、モデルに関する情報はインスタンスの属性として格納されます。試しに取り出して確認してみます。
a = model.coef_ # array([49.79746387])
b = model.intercept_ # -5792.055412615383
scikit-learnのモデルパラメータには最後にアンダーバー_がつきます。単回帰モデルの場合、coef_が傾きでintercept_は切片です。中学で習ったy = ax + bのaとbですね。知ってる!知ってるぞ!
モデルと言うとなんか近代的な感じがしますが、要するにこの「y = ax + bのようなxからyを求める数式」のことです。この数式を求めたのが先程の.fit()メソッド。
ということでどんな直線に回帰されたのかプロットして見てみます。
import numpy as np
import matplotlib.pyplot as plt
x_line = np.linspace(150,250) # 元のxの近くに合わせて150~250の数列を作成
y_line = a * x_line + b
plt.scatter(x,y) # 元のデータを散布
plt.plot(x_line,y_line) # フィッティングした回帰直線
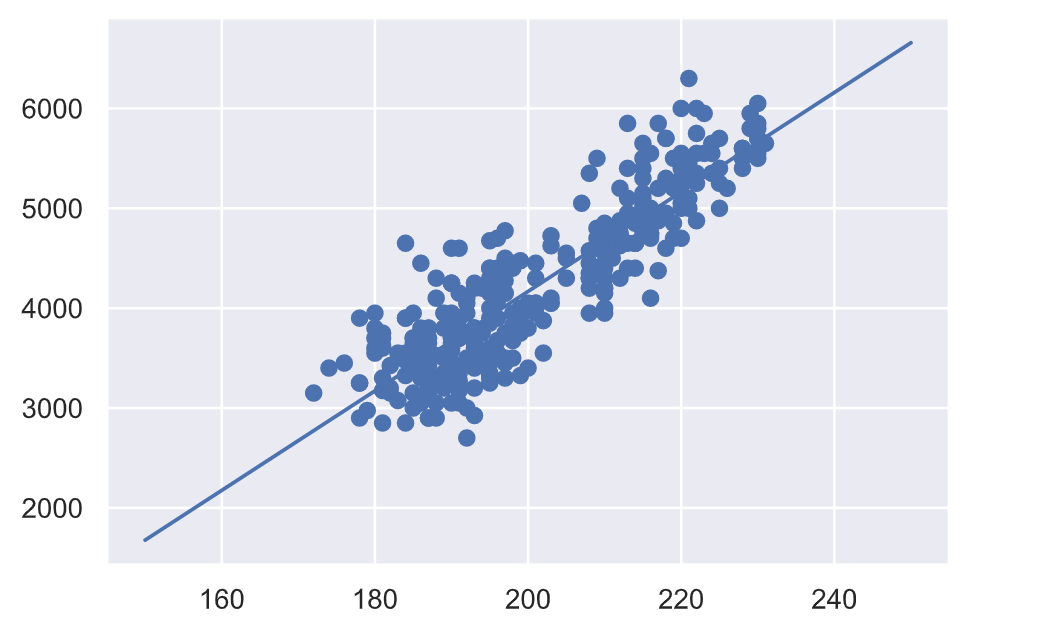
それっぽい線が引けてますね。これが単回帰で作成したモデルです。
機械学習の手順5. 予測
ここでは作成したモデルに新しい未知のデータを適用して予測します。機械学習のキモですね。
xfit = df.flipper_length.values[-10:] # 未知のデータ
Xfit = xfit.reshape(len(xfit),1)
yfit = model.predict(Xfit) # 予測
.predict()メソッドでモデルにあてはめたときの予測値が出てきます。要するに、先程みたy = ax + bというモデルにxを代入したときの答えyが得られます。
早速プロットしてみましょう。ついでに元のデータセットから答えがわかっているので、答えもプロットしてみます。
plt.scatter(xfit, yfit)
plt.plot(xfit, yfit)
plt.scatter(xfit, df.body_mass.values[-10:])
結果はこちら。
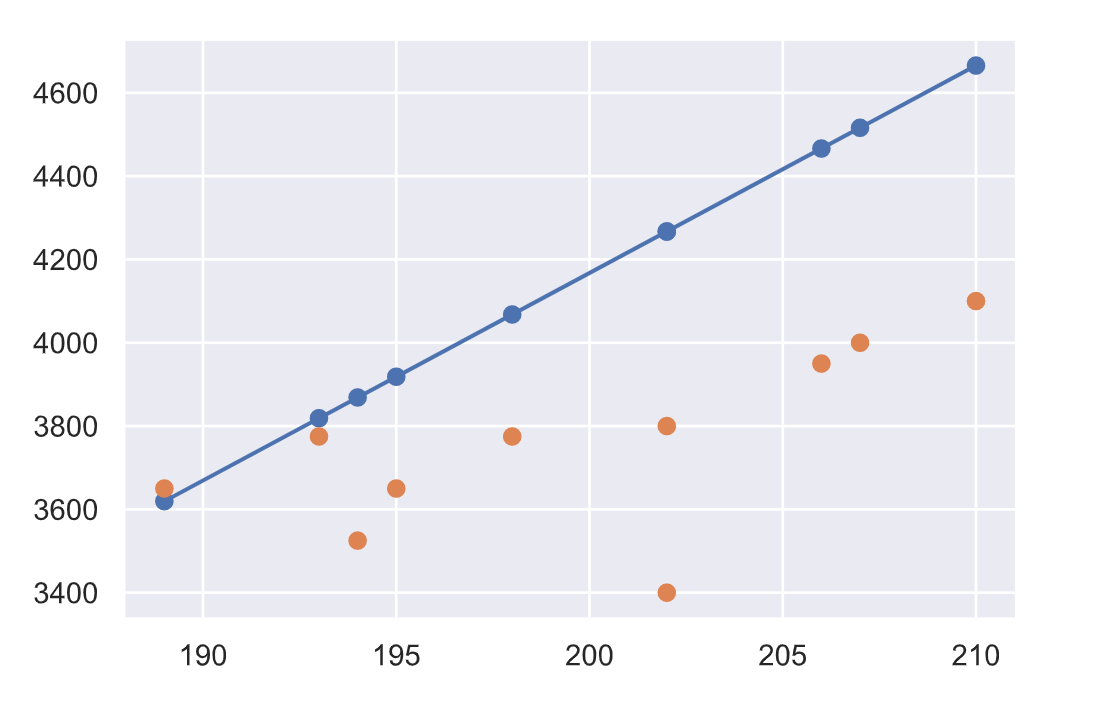
お、おう...。
青が予測値で橙が真のデータですね。グラフの軸がズームフォーカスされてるので予測値と答えが相当かけ離れている用に見えますが、数百グラム以内の誤差で予測できています。
以上で、機械学習の流れは終了です!
今回の例はぶっちゃけ最小二乗法で解ける簡単な回帰ですが、このような予測を目的として、データセットからモデルにフィッティングさせて未知のデータへ活用する、というのが機械学習の基本です。
まとめ
というわけで、今回はペンギンデータセットとscikit-learnを使って基本的な機械学習の流れを、「教師あり学習の単回帰モデル」を例に追ってみました。
次回は他のモデルについても見ていこうと思います。
それでは〜。
今回実行したPythonコードおさらい 〜 機械学習部分
# 1. モデル選定
from sklearn.linear_model import LinearRegression
# 2. インスタンス作成とハイパーパラメータの設定
model = LinearRegression(fit_intercept=True)
# 3. 学習用データの設定
y = df.body_mass.values[:-10]
x = df.flipper_length.values[:-10]
y.reshape(len(y),1)
X = x.reshape(len(x),1)
# 4. フィッティング
model.fit(X,y)
# 5. 未知のデータの予測
xfit = df.flipper_length.values[-10:]
Xfit = xfit.reshape(len(xfit),1)
yfit = model.predict(Xfit)
# オマケ. 可視化と答え合わせ
import matplotlib.pyplot as plt
plt.scatter(xfit, yfit)
plt.plot(xfit, yfit)
plt.scatter(xfit, df.body_mass.values[-10:])

