ペンギンデータセットでデータサイエンス入門 〜 特徴行列の可視化編【Python/seaborn/palmerpenguins】

目次
こんにちは。
さて、昨今データサイエンス界隈を賑わせているpalmerpenguinsなるペンギンデータセット。前回の記事でデータ加工して分析の準備が整いました。
今回は実際にペンギンデータセットで特徴行列と目的配列の可視化を学びましょう。
という記事です。
よろしく。
ちなみに本記事ではプログラムにPython3を使います。
過去の関連記事はこちらです。
データセットの準備
今回使うライブラリをインストールします。入ってなければpip installで入れましょう。
import pandas as pd
import seaborn as sns
前回作ったデータセットを読み込んで、必要な列だけ取り出します。列名は単位がついていて長いので、使いやすいように短く変換します。
df = pd.read_csv('penguins.csv')
df.columns.tolist()
use_col = [
'species',
# 'island',
'bill_length_mm',
'bill_depth_mm',
'flipper_length_mm',
'body_mass_g',
# 'sex',
# 'year',
]
df = df[use_col]
df = df.rename(columns={
'bill_length_mm':'bill_length',
'bill_depth_mm':'bill_depth',
'flipper_length_mm':'flipper_length',
'body_mass_g':'body_mass'
})
こんな感じのデータになりました。
特徴行列と目的配列
今回のデータセットでは、species(ペンギンの種類)を、他の列を特徴として推定していきたいと思います。
予測したい列のことを目的配列というので、今回はspeciesが目的配列ということになります。
また、残り4つが目的配列を推定するための特徴です。この特徴の列たちを特徴行列といいます。
seabornでデータを可視化する
早速ですが、どんなデータかを見てみましょう。speciesを目的配列として指定して、ペアプロットで多次元データの相関を調べられます。
sns.set()
sns.pairplot(df, hue='species', size=1.5)
出力はこちら。データの分布が散布図とカーネル密度推定(ヒストグラムのようなやつ)で出てきます。
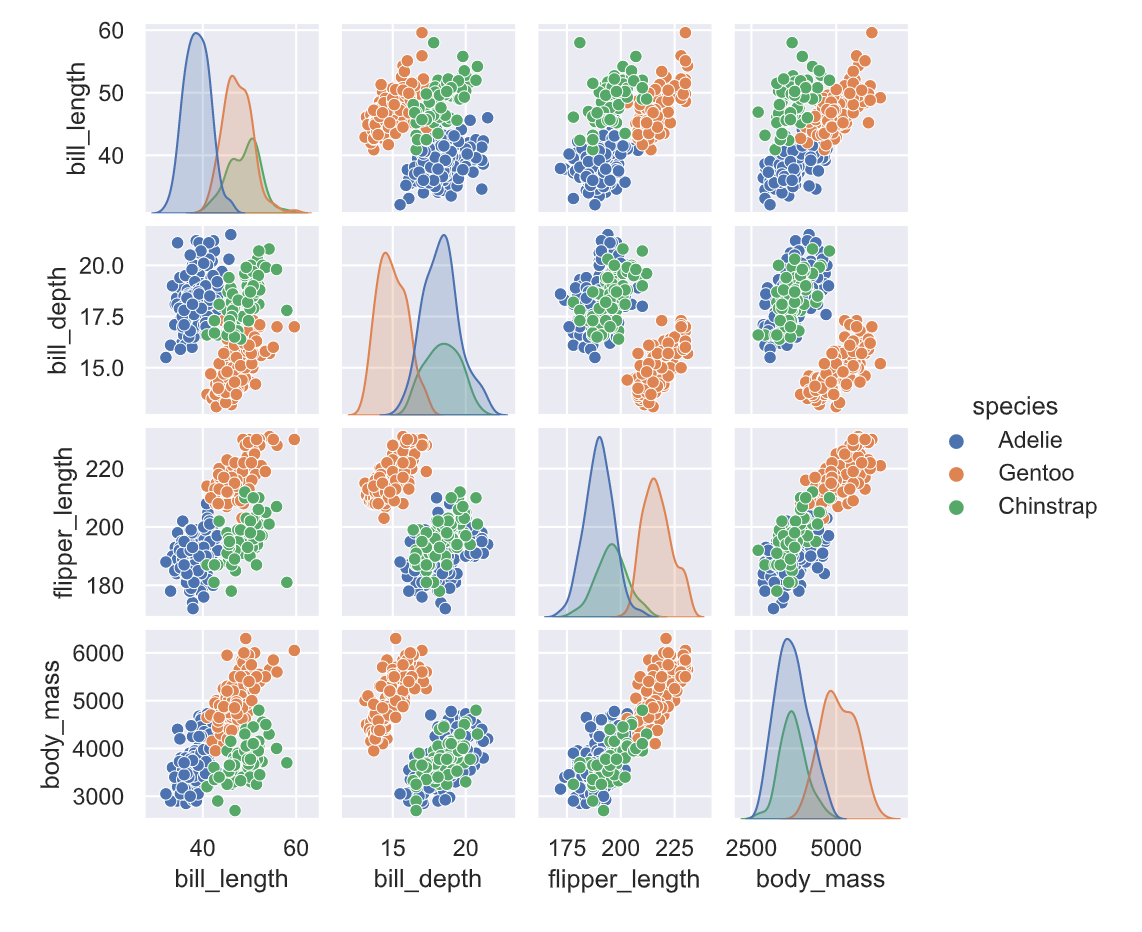
色分けが推定したいspeciesです。なんとなく、それぞれの分布が塊になって集まっているのがわかりますね。つまり、それぞれの特徴からspeciesがなんとなく推定できそうだということがわかります。
たとえば左から2列目の1番下を見てわかることは、bill_depth(くちばしの太さ)とbosy_mass(体重)を調べると、橙色のGentoo(ジェンツーペンギン)は判別できそうですが、緑色のChinstrap(ヒゲペンギン)と青色のAdelie(アデリーペンギン)の識別はできなさそうだとわかります。
こんな2行でたくさんグラフが出てきて分析した気分になれるのは凄いですね。MatplotlibよりもSeabornの方がpandasのデータフレームを可視化するのに向いています。(Matplotlibの方が、pandasより歴史が古いみたいです。)
こうして分析や推定に取り組む前に、ひとまずデータセットを可視化してデータの傾向を眺めてみることで、戦略が立てやすくなります。
まとめ
ということで、今回はPythonのデータセット可視化ライブラリseabornを使ってペンギンデータセットの目的配列と特徴行列を可視化してみました。
データが複数の特徴を持つ場合に、特徴行列の関係をさくっと調べられるので重宝しますね。
次回はscikit-learnを使って推定していこうと思います。だんだん機械学習っぽくなってきました。
それでは〜

