パワポ(パワーポイント)資料のスライドにPythonプログラムで表を自動作成する方法【python-pptx/PowerPoint/pandas】

目次
こんにちは。
ふと仕事でパワポ資料を作りながら、「これプログラムで自動で作れないかな」と思いつき、調べてみたら案の定Pythonでできそうなので、まとめてみました。
チームや部署で同じフォーマットを何回も作るみたいなことがあれば役立ちそうです。
今回はスライド資料に挿入する「表」を作ってみます。表データはpandasのDataFrameで準備します。
ちなみに、本記事のプログラムの動作確認はPython3.8で行っています。
必要なライブラリ python-pptxのインストール
使用するライブラリはpython-pptxです。pythonのインストールはここでは割愛。
pip install python-pptx
ちなみにpython-pptxの詳しい使い方はこちら。英語ドキュメントです。
表データ(pandas DataFrame)を準備する
表に挿入するデータとして、pythonで表形式データセットを扱う際の定番であるpandas DataFrameを使用します。
今回はデータセットの例として、このブログでよく使うペンギンデータセットを使用します。
import pandas as pd
# CSVファイル読み込み
df = pd.read_csv('penguins.csv')
# 使用する列の選択
use_col = ['species','bill_length_mm','bill_depth_mm','flipper_length_mm','body_mass_g']
# speciesごとに平均値をグループ集計する (小数点以下2桁で丸める)
df = df[use_col].groupby('species').mean().round(2)
こんな感じのデータです。ペンギンの種類ごとにくちばしの長さや体重が表になっています。
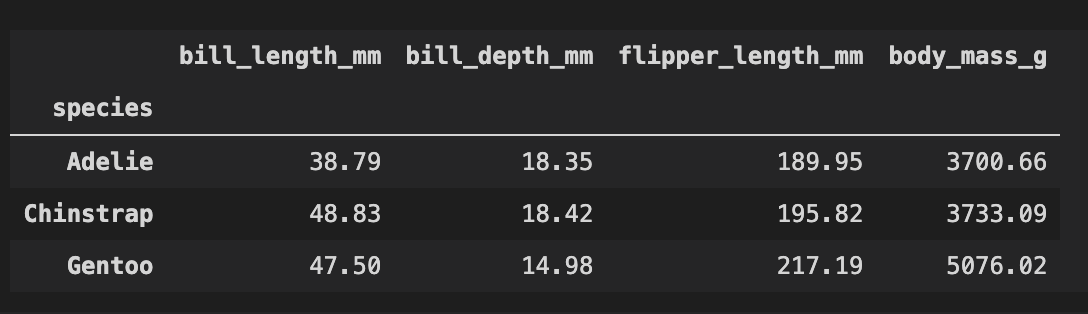
この図をそのままパワポに貼ればいいじゃん。。ってのは今回はナシの方向で。
Pythonでスライドを作ってみる
先程のDataFrameを挿入したスライドを生成してみます。
最初はお決まりの形式。ライブラリをインポートして、レイアウト設定とshapesというスライド用のオブジェクトを作成します。
from pptx import Presentation
from pptx.util import Inches
prs = Presentation()
title_only_slide_layout = prs.slide_layouts[5]
slide = prs.slides.add_slide(title_only_slide_layout)
shapes = slide.shapes
挿入する表(テーブル)のサイズと位置を指定する
次に挿入する表(テーブル)の設定をします。設定項目は以下です。
- スライドのタイトル(文字列)
- 行と列の数(数値)
- ポジション(左上からインチ単位)
- テーブルの幅と高さ(インチ単位)
shapes.title.text = 'Penguins' # スライドのタイトル
# 表(テーブル)の設定
rows = 1 + len(df) # ヘッダ用に1行追加
cols = 1 + len(df.columns) # インデックス用に1列追加
# テーブルサイズはスライド全体の見栄えに関わるので固定
left = Inches(1.0)
top = Inches(2.0)
width = Inches(8.0)
height = Inches(1.0)
# 上記設定でテーブルオブジェクト作成
table = shapes.add_table(rows, cols, left, top, width, height).table
デフォルトでパワーポイントのスライドの幅は10インチなので、左に1インチ、幅を8インチにすることで、中央寄せの表にします。ちなみにスライドの縦の長さは7.5インチです。
データセットのサイズが変わっても使い回せるように、行と列の数はDataFrameのプロパティから持ってくるようにしています。
列(カラム)の幅を設定する
続いて列の幅を指定します。今回はindexにペンギンの種類を書き、他の列に特徴量の数値を割り当てるため、indexとデータ列にそれぞれ別の幅を指定します。
# カラムの幅を設定
table.columns[0].width = Inches(2.0) # 0列目はindex列
for i in range(cols):
table.columns[i].width = Inches(6.0/len(df.columns)) # 6/4 = 1.5
見栄えを整えるため、全体の幅が、前の節で指定したwidthと一致するよう気をつけます。そのため、表の幅8.0からindexの幅2.0を引いた残りである6.0をDataFrameの列数で割っています。
列幅は一つずつ指定する仕様なので、for文で列の数だけ繰り返しています。
テーブルの一番上(ヘッダ)の行のテキストを記載する
通常、表の一番上の行には列の説明を記載しますので、データフレームで言うところのdf.columnsを記載していきます。
table.cell(x,y)のうち、1番目の引数xが行番号を表し、2番目の引数yが列番号を表します。1番左上のセル(0,0)はDataFrameのdf.columnsではなく、index名なのでdf.index.nameを入れます。
# ヘッダのテキストをセット
table.cell(0, 0).text = df.index.name # df.index.nameは、'species'
for i,c in enumerate(df.columns):
table.cell(0, i+1).text = c
一番上の行番号は0なので、xは0で固定です。
2列目以降のデータ列はfor文でDataFrameの列の数だけセットします。
ちなみに、enumerateは配列のindex番号と中身の値をセットで返してくれるので、for文で番号と値が両方欲しいときに便利です。
テーブルの一番左(インデックス)の列にテキストを記載する
一番左の列はインデックスとなるので、データフレームのindexから記載します。一個前のヘッダと同様の方法です。
# インデックスのテキストをセット
for i,n in enumerate(df.index):
table.cell(i+1, 0).text = n
今回は一番左の列に大してfor文で繰り返し処理をしたいので、cellの2番目の引数が0固定です。
テーブルの中身(ボディ)の値を記載する
行と列の二重for文で記載していきます。セルの中身はテキストにしか対応していないため、数値データそのままセルに代入しようとするとエラーになります。なので、str()で文字列に変換します。
# テーブルのボディの値をセット
for i in range(len(df)):
for j,v in enumerate(df.iloc[i].values):
table.cell(i+1, j+1).text = str(v)
df.iloc[i].valuesは各行の中身の値が入った配列です。
cell()の番号をそれぞれ+1するのは、記載済みのインデックス列とヘッダ行を除くためです。
ここまでで、表の設定と値の記載がすべて完了しました。
PowerPointファイルに出力する
以下の文でファイル名を指定して.pptxとしてファイル出力できます。
prs.save('penguins.pptx')
結果↓
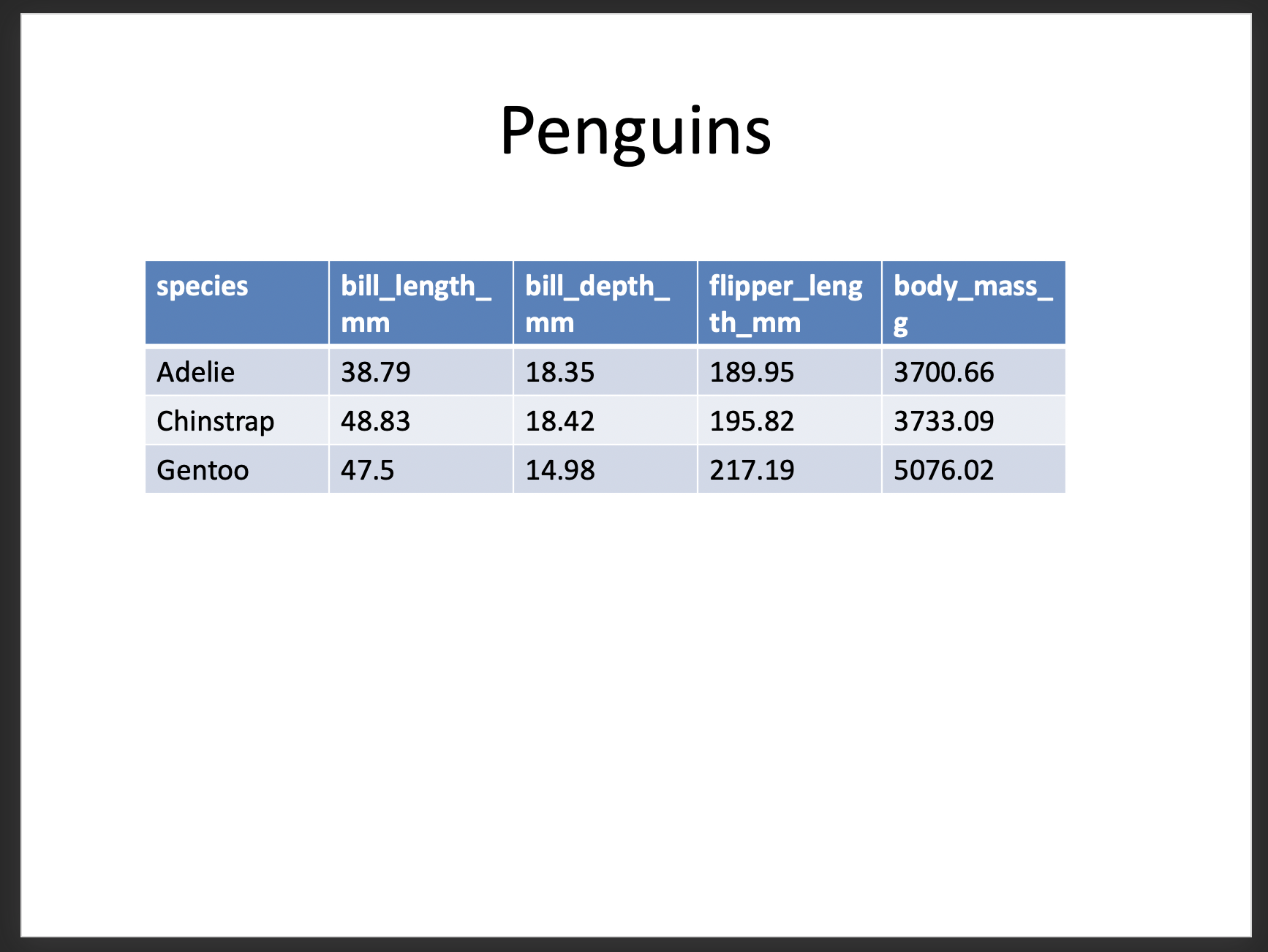
できてる。すごい。
これくらいのデータ量なら手で転記できますが、データ量が増えたときに記載ミス(ヒューマンエラー)が出そうなので、Pythonは効果を発揮しそうです!
まとめ
というわけで今回はPowerPointファイルをPythonで作成して、pandasのデータフレームから表を作ってみました。
表以外にも色々な使い方を試してみたい方は、こちらのpython-pptxドキュメントのexampleが参考になります。
それでは〜

