年代別の平均的な貯蓄額について調べてみた
目次
こんにちは。
貯金やお金が大好きな一般人です。
毎月このブログでは家計を振り返ったりしていますが、「そういえば周りの人達ってどれくらいお金を貯めていたりするんだろう」と気になったので調べてみました。
グラフはPythonのMatplotlibで作ってみようと思います。
データソース
以下の「金融資産の状況等」を使用しました。
知るぽると 金融広報中央委員会 各種分類別データ(令和元年)
世論調査を元にしたデータです。
問2(a)が「金融資産保有額(金融資産保有世帯)」です。金融資産なので、現金だけではなく株や債権も含まれています。
母数は2461世帯で、各年代300~600サンプルです。20歳代は37世帯しかサンプルがないので、あまり参考にしなくてもよいかも。
年代別の平均的な貯蓄
表にしてみるとこんな感じ。
| 世帯主の年代 | 平均[万円] | 中央値[万円] |
|---|---|---|
| 20歳代 | 220 | 165 |
| 30歳代 | 640 | 355 |
| 40歳代 | 880 | 550 |
| 50歳代 | 1,574 | 1,000 |
| 60歳代 | 2,203 | 1,200 |
| 70歳以上 | 1,978 | 1,100 |
平均は一部の富裕層に爆上げされてる感が否めないので中央値を参考にします。
三十代で355万円というのは、なんとなく心許無い感じがしますね...!
年間200万円で生活していたら、仕事をせずとも2年弱は生きられる感じでしょうか。
そう考えると、割と余裕があるような気もします。
金融資産保有額の分布
もう少し詳しく世代別の分布を見てみます。
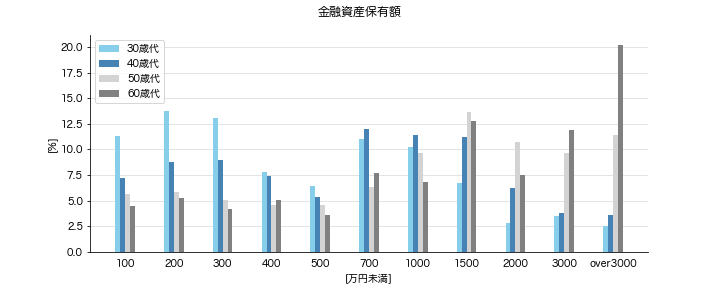
横軸の読み方は、「100」だと100万円未満で、「200」だと「100万円以上、200万円未満」です。
世帯主の年代が30歳代の場合(薄い水色)は、確かに分布のピークは200~300付近にありそうです。中央値で見た感覚に近いですね。
しかし、わずかに双峰性を持っていて、2つめの山のピークが700~1000付近にもありそうです。
300~500で落ち込むのは結構不思議ですね。理由を知っている方がいたらTwitterの@メンションかDMでこっそり教えてほしいです。
意外と多い!1000万円以上保有世帯
500万円、700万円、1000万円以上保有している層の割合の合計を見てましょう。
値は、上の分布のグラフで、横軸から右側の[%]をすべて合計したものです。
| 世帯主の年代 | 500以上[%] | 700以上[%] | 1000以上[%] |
|---|---|---|---|
| 30歳代 | 36.7 | 25.7 | 15.5 |
| 40歳代 | 48.2 | 36.2 | 24.8 |
| 50歳代 | 61.5 | 55.2 | 45.5 |
| 60歳代 | 66.9 | 59.2 | 52.4 |
当然ですが、年代が上がるにつれて保有世帯の割合はどんどん増えていきますね。
30歳代では1/3以上の世帯が500万円以上保有していて、15%以上の世帯が1000万円以上保有しているとのこと。
1000万円保有できていれば比較的優秀な貯蓄額と言えそうな結果ですね。
まとめ
というわけで、世論調査のデータを元に年代別の貯蓄額について調べてみました。
30代の中央値は355万ということで、それ以上貯蓄できていれば上位側には入れていそう。
1000万円以上あれば上位15%の蓄財優等生と言えそうです。
あまり人と比べすぎるのもよくないですが、私も1000万円を目指して頑張りたいと思います〜。
【参考】Pythonの可視化プログラム
グラフは以下のコードで出力しています。
matplotlibのインポートと日本語化
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'sans-serif'
rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio']
金融資産保有額
cols = ['30歳代','40歳代','50歳代','60歳代']
colors = ['skyblue','steelblue','lightgrey','grey']
fig = plt.figure(figsize=(10, 4))
fig.suptitle('金融資産保有額')
ax = fig.add_subplot(111,xlabel='[万円未満]', ylabel='[%]')
w = 0.1
for i,col in enumerate(cols):
ax.bar(
df.index + w * (i-len(cols)/2),
df.loc[:,col],
label=col,
fc=colors[i],
width=w,
align='edge',
zorder=10)
ax.tick_params(bottom=False)
ax.set_xticks(df.index)
ax.set_xticklabels(df['index'], rotation=0, ha='center')
ax.grid(axis='y', c='gainsboro', zorder=9)
ax.legend()
[ax.spines[side].set_visible(False) for side in ['right','top']]
データセットは、dfのcolsの列ごとに[%]の数値が入っています。
以上、ご参考まで。

